My little R&D into wiki domains at http://www.racerkidz.com seems to work fine - I add a feature evry now and then.
You can register a club, describe a racing schedule, then racers can add it to their profile and automatically, via the magic of wiki xpath, see the racing calendar and the map...
You can give it a try without an account from the home page.
I also experimentally used it to create simple blogs, like this enduro school. A blog has posts and that's that, see its domain definition.
Cheers!
Friday, August 24, 2012
Sunday, March 28, 2010
Killing an annoying warning
The most annoying warning ever has been haunting me for a while.
I refuse to include and move around large unnecessary libraries to deal with XML and XPATH just because Sun considers themselves the center of the universe and their internal libraries somehow more important then mine. In short, they figured there should be no way to remove this warning, although, in this case, they copied code from apache into their own libraries.
Well, the solution is rather simple. Most likely everyone has specific XML wrappers. Just put them in their own project, disable the java/scala builders. Then, build it manually, create a jar file and check it in.
Then, in all the other projects, use this jar directly. Since the jar is already compiled, the annoying warning is no more.
See for instance my xml utilities, at http://github.com/razie/razxml
What's more, I don't actually use the XML stuff directly. I wrapped it all in pretty much one single class, using XPATH for access. It's simple, fast enough and makes for very simple code:
For all xml data access, you should limit yourself to the xpe/xpl/xpa methods described in an earlier post (http://blog.homecloud.ca/2010/02/one-xpath-to-rule-them-all.html). So, use something like this instead: http://github.com/razie/razxml/blob/master/src/razie/base/data/XmlDoc.java
Cheers.
[javac] /home/razvanc/workspace7u6/razxml/src/razie/base/data/RiXmlUtils.java:160: warning: com.sun.org.apache.xpath.internal.objects.XObject is Sun proprietary API and may be removed in a future release
I refuse to include and move around large unnecessary libraries to deal with XML and XPATH just because Sun considers themselves the center of the universe and their internal libraries somehow more important then mine. In short, they figured there should be no way to remove this warning, although, in this case, they copied code from apache into their own libraries.
Well, the solution is rather simple. Most likely everyone has specific XML wrappers. Just put them in their own project, disable the java/scala builders. Then, build it manually, create a jar file and check it in.
Then, in all the other projects, use this jar directly. Since the jar is already compiled, the annoying warning is no more.
See for instance my xml utilities, at http://github.com/razie/razxml
What's more, I don't actually use the XML stuff directly. I wrapped it all in pretty much one single class, using XPATH for access. It's simple, fast enough and makes for very simple code:
Reg.doc(MediaConfig.MEDIA_CONFIG).xpa(
"/config/storage/host[@name='" + Agents.me().name + "']/media/@localdir"
)
For all xml data access, you should limit yourself to the xpe/xpl/xpa methods described in an earlier post (http://blog.homecloud.ca/2010/02/one-xpath-to-rule-them-all.html). So, use something like this instead: http://github.com/razie/razxml/blob/master/src/razie/base/data/XmlDoc.java
Cheers.
Saturday, March 13, 2010
The Option monad pattern thing
This informative post is consolidated in the new blog, at:
http://www.coolscala.com/wiki/Blog:Cool_Scala/Post:The_Option_monad_pattern_thing
... where we take a closer look at the Option type of Scala, the monadic aspect of it and see how we can use it to inspire new patterns and new ways of looking at the code we write.
(Sorry - original content was removed from here, to avoid duplicates).
http://www.coolscala.com/wiki/Blog:Cool_Scala/Post:The_Option_monad_pattern_thing
... where we take a closer look at the Option type of Scala, the monadic aspect of it and see how we can use it to inspire new patterns and new ways of looking at the code we write.
Monday, March 1, 2010
Scripster - interactive scala REPL using telnet, http etc
As mentioned before, I think that all apps must alllow scripted/programatic access to their objects.
I created a simple interactive gate to acces the scala REPL in any scala process. It only uses one port and supports telnet, http and swing:
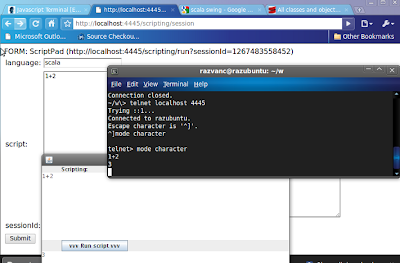
The graphics are based on my 20widgets project, with the addition of a ScriptPad widget.
Content assist is only available in the telnet version (sic!). I will work to find some nice syntax-colored controls for the web version. Switch to character mode ("mode character" on ubuntu or default on windows) and use TAB to see a list of options. Right now it's a demo only, I need to find the parser's APIs to get the real content assist options ;)
You can download the single scripster-dist.jar file from my razpub project download, at http://code.google.com/p/razpub/ and run the example with this command line (replace /host/bin/scala with your $SCALA_HOME) :
To use it in your process, put these jars in your classpath and use this:
For further tweaking, look at the code yourself, at http://github.com/razie/scripster/tree/master/src/razie/scripster/
If you want to keep in touch with the evolution of scripster or my other related endeavours, subscribe to the RSS feed or twitter/razie.
Enjoy!
I created a simple interactive gate to acces the scala REPL in any scala process. It only uses one port and supports telnet, http and swing:

The graphics are based on my 20widgets project, with the addition of a ScriptPad widget.
Content assist is only available in the telnet version (sic!). I will work to find some nice syntax-colored controls for the web version. Switch to character mode ("mode character" on ubuntu or default on windows) and use TAB to see a list of options. Right now it's a demo only, I need to find the parser's APIs to get the real content assist options ;)
You can download the single scripster-dist.jar file from my razpub project download, at http://code.google.com/p/razpub/ and run the example with this command line (replace /host/bin/scala with your $SCALA_HOME) :
java -classpath ./scripster-dist.jar:/host/bin/scala/lib/scala-library.jar:/host/bin/scala/lib/scala-compiler.jar:/host/bin/scala/lib/scala-swing.jar razie.scripster.JScalapSwing
To use it in your process, put these jars in your classpath and use this:
razie.scripster.Scripster.create(4445)where 4445 is the port you want to use, see the razie.scripster.MainScripster for an example. To enable the swing version, use the swing jars as well and see the razie.scripster.MainSwingScripster class for an example.
For further tweaking, look at the code yourself, at http://github.com/razie/scripster/tree/master/src/razie/scripster/
If you want to keep in touch with the evolution of scripster or my other related endeavours, subscribe to the RSS feed or twitter/razie.
Scripster's main page, kept up-to-date, is at http://wiki.homecloud.ca/scripster. There's also an online live demo at http://scripster.codewitter.com.
Enjoy!
Saturday, February 6, 2010
One XPath to rule them all!
ABSTRACT: there's a million ways to access (data, objects, tables etc) these days and probably new ones are created every milisecond. What if we can figure out one that can be used anywhere?
Think about it!
/Universe/Planets/Planet[@name=='earth']/@position
XPath was created as a natural way to address elements in an XML document. One specifies the path - starting from the root node - to the element you are addressing. Conditions help you select the right nodes from many (lists) and you can address nodes or their attributes.
Extending it to addressing trees is strait-forward, so we can apply the same paradigm to any tree-structure, like Java beans...see for instance this Apache library: http://commons.apache.org/jxpath/
Come to think about it, all direct acyclical graphs fit in the same category...of course, with small differences: selecting an edge from among many possible types and lack of a root...so, some extensions are in order:
/Person[@name='John']/{hasFriends}Person
What hapens here is that the node of type Person that meets the criteria was selected as the start node and then the graph walk begins. From the many relationships tying humans together, the ones of type "hasFriends" are followed and not "hasChildren".
Yeah, you got it - even cycles are handled this way simply because as the path is walked, it reaches an end...
And... yeah, you got it again: UML domain model of classes with associations...it can describe any model you may use internally or present to clients...so we can handle pretty much any domain model described in an UML class diagram.
There.
I found myself needing four basic operations:
- xpe : T - /** find one element */
- xpl : List[T] - /** find a list of elements */
- xpa : String - /** find one attribute */
- xpla : List[String] - /** find a list of attributes */
For the sake of being concise, I will represent this new "data access interface"as either of the versions below (with explicit type and start node or implicit):
val me = XP[Person] xpe ("/Person[@areGroovy=='yeah, baby!']") from john
val minime = xpe ("/Person[@areGroovy=='yeah, baby!']")
So, why would this be useful?
Frankly, I'm growing old(er) and tired of all the non-sensical APIs that pop-up all the time everywhere: My application is unique! My domain model is complex! Everything could be an Object, but so what? I'm smarter! I know better!
My answer is: nope, your application's domain model is a class diagram and your actual objects thus form a graph. I don't need you to inven new ways to interact with your objects, over a million protocols and a million forms, when we can unify it all.
It's a very simple pattern. All it requires is that users understand basic modelling and the application's domain. The same expressions would be used by everyone...if not, at least the same pattern. No more gazillion interfaces and gazillion models.
Think about communication. Can be done in 2 ways:
1) blah blah blah can blah blah when blah blah and then some more blah blah
2) UML
You give me your domain model and, since you implement this simple no non-sense path-based model access, that's all I need to know. What you should focus on is documenting what the actual objects in your model: what they mean and what I can do with them once I have them.
This also enables generic graphical software creation. All I need is to have your domain model and then I can use a generic path composition tool (pick a node from a tree if you want).
It interactively explores the domain model, picking elements on the way.
In my integration work, I would love it if I didn't have to waste time writing stupidifying code over a miriad protocols just to get to what I needed.
If you're wondering how exactly the data should be accessed, we'll cover that in one of the next posts on this subject, in the mean time, take JOSH to heart: JSON, OSGI, Scala, Http...thank you, Gray Lens Man!
Enough for now - will continue soon...if you're interested and impatient, you can play with my prototype at http://github.com/razie/razbase/blob/master/src/razie/XP.scala
Tuesday, November 3, 2009
One Person
Abstract: You are one person, using multiple devices - why shouldn't your stuff follow YOU rather than the device? Since we don't like depending on a 3rd party, the "home" cloud is the answer?
--------- Issue
Most programs today are isolated islands of functionality. The Web 2.0 transforms that, allowing you to mesh together pieces of functionality and information. The same is not true on personal computing platforms i.e. your laptop.
The bookmarks you store on your laptop can't be accessed when you're on the desktop at home and vice-versa. Same for your notes and pretty much anything, unless you manually copy them etc.
Option 1: store information on the web (centralised location). The one benefit of this is the ability to use that information from anywhere and any device. The drawbacks include big-brother and relying on a 3rd party for availability (including backup etc). Of course, the need to be online...although smart solutions can use local caches.
The big brother issue is getting worse. As much as you trust ALL levels of government of ALL countries that may have a claim on you or your property AND all their agencies, there are more and more corporations that mine all kinds of data about your person, for different reasons. Some as benign as offering you a new credit card and some as bad as credit recovery, setting insurance premiums etc. Let's not forget identity theft.
Option 2: use a home server. Basically, almost everyone has by now a server at home, which is constantly connected to the big Cloud, whether you're downloading movies or host your own blog. Why not use that instead of a 3rd party, to serve other stuff.
There are many a solutions to host your own stuff and access/share from/with the world. There's lots of software to serve security camera feeds, TV programs from your home, the Windows Home Server etc...the trend is already in place.
Having resolved (somewhat) the big brother and 3rd party dependency problem, there's still the issue of needing to be online.
Option 3: fully distributed and synchronised personal cloud. Store information locally, on the device that creates it (like on the work desktop where you save a favourite) and synchronise all devices (peer-to-peer or properly distributed solution). The only drawback is lack of on-demand availability of the information from other devices, until the sync occurs. This can be solved however by connecting your own PC to the net...or combining with option 1 or rather 2.
------------- Vision
The vision is that of you and your information following you. In fact it's not following you...it's just "there" for you to use. Whatever computer in your "home" cloud you use, your information is there.
I mean, will you upload ALL your favourites on facebook, just so you have them available in the living room, when you get home? I don't think so!
The solution is the logical conclusion of the same debate of distributed vs. centralised that's been raging for the past few decades. All those "in the know" know that it's a wave function. Now we may be heading towards the climax of centralised internet based clouds, but, as more PERSONAL processing power becomes more online, split between more types of personal devices and connected, the trend in the other way is just a matter of time...wave, right?
So, I dream of many agents, running on many personal devices, connected in your "personal" or "home" cloud, sharing all kinds of information and cooperating.
So, when you mark a "favourite" on your work desktop, it automatically gets replicated on your laptop, your home desktop (the cloud's gateway) and all the computers in the house, including the one in the living-room. There's nothing left to do but, when you get home, sit down and enjoy it on the big screen!
No 3rd party knows you enjoy that hardcore woodworking show or that you're trying to fix the toilet seat, no insurance company can mine that you once watched 3 illegal races on youtube etc...all usually available on your facebook or whathaveyou.
-------------- The social aspect
Today, no application is complete without considering the social aspect. You could obviously push some of your favourites to facebook, or share with friends in "friend" clouds.
-------------- Flexibility, customisation
Probably the biggest gain from a "central" cloud, like gmail etc is flexibility and customisability. Gmail is gmail is gmail. That's exactly what it does and, while you may change it's fonts and even access it remotely via an IMAP or http API (thank you, Google) that's still exactly what it does.
A personal cloud, though, can be customised. You decide what it does and how it does it.
-------------- try it
If you want to play with such an agent, try a preview of mine, at http://razpub.googlecode.com/downloads
Read more about it at http://wiki.homecloud.ca
You can even try the remote favourites sharing prototype...follow this link after you downloaded, installed it and started it on several computers: http://localhost:4444/mutant/capture.html - After capturing, go to another computer in your home cloud and see the links at: http://localhost:4444/mutant/asset/Link
This is written as of version 0.x so the links may change - the use case however will be maintained up-to-date in the wiki, at http://wiki.homecloud.ca/savedlink
--------- Issue
Most programs today are isolated islands of functionality. The Web 2.0 transforms that, allowing you to mesh together pieces of functionality and information. The same is not true on personal computing platforms i.e. your laptop.
The bookmarks you store on your laptop can't be accessed when you're on the desktop at home and vice-versa. Same for your notes and pretty much anything, unless you manually copy them etc.
Option 1: store information on the web (centralised location). The one benefit of this is the ability to use that information from anywhere and any device. The drawbacks include big-brother and relying on a 3rd party for availability (including backup etc). Of course, the need to be online...although smart solutions can use local caches.
The big brother issue is getting worse. As much as you trust ALL levels of government of ALL countries that may have a claim on you or your property AND all their agencies, there are more and more corporations that mine all kinds of data about your person, for different reasons. Some as benign as offering you a new credit card and some as bad as credit recovery, setting insurance premiums etc. Let's not forget identity theft.
Option 2: use a home server. Basically, almost everyone has by now a server at home, which is constantly connected to the big Cloud, whether you're downloading movies or host your own blog. Why not use that instead of a 3rd party, to serve other stuff.
There are many a solutions to host your own stuff and access/share from/with the world. There's lots of software to serve security camera feeds, TV programs from your home, the Windows Home Server etc...the trend is already in place.
Having resolved (somewhat) the big brother and 3rd party dependency problem, there's still the issue of needing to be online.
Option 3: fully distributed and synchronised personal cloud. Store information locally, on the device that creates it (like on the work desktop where you save a favourite) and synchronise all devices (peer-to-peer or properly distributed solution). The only drawback is lack of on-demand availability of the information from other devices, until the sync occurs. This can be solved however by connecting your own PC to the net...or combining with option 1 or rather 2.
------------- Vision
The vision is that of you and your information following you. In fact it's not following you...it's just "there" for you to use. Whatever computer in your "home" cloud you use, your information is there.
I mean, will you upload ALL your favourites on facebook, just so you have them available in the living room, when you get home? I don't think so!
The solution is the logical conclusion of the same debate of distributed vs. centralised that's been raging for the past few decades. All those "in the know" know that it's a wave function. Now we may be heading towards the climax of centralised internet based clouds, but, as more PERSONAL processing power becomes more online, split between more types of personal devices and connected, the trend in the other way is just a matter of time...wave, right?
So, I dream of many agents, running on many personal devices, connected in your "personal" or "home" cloud, sharing all kinds of information and cooperating.
So, when you mark a "favourite" on your work desktop, it automatically gets replicated on your laptop, your home desktop (the cloud's gateway) and all the computers in the house, including the one in the living-room. There's nothing left to do but, when you get home, sit down and enjoy it on the big screen!
No 3rd party knows you enjoy that hardcore woodworking show or that you're trying to fix the toilet seat, no insurance company can mine that you once watched 3 illegal races on youtube etc...all usually available on your facebook or whathaveyou.
-------------- The social aspect
Today, no application is complete without considering the social aspect. You could obviously push some of your favourites to facebook, or share with friends in "friend" clouds.
-------------- Flexibility, customisation
Probably the biggest gain from a "central" cloud, like gmail etc is flexibility and customisability. Gmail is gmail is gmail. That's exactly what it does and, while you may change it's fonts and even access it remotely via an IMAP or http API (thank you, Google) that's still exactly what it does.
A personal cloud, though, can be customised. You decide what it does and how it does it.
-------------- try it
If you want to play with such an agent, try a preview of mine, at http://razpub.googlecode.com/downloads
Read more about it at http://wiki.homecloud.ca
You can even try the remote favourites sharing prototype...follow this link after you downloaded, installed it and started it on several computers: http://localhost:4444/mutant/capture.html - After capturing, go to another computer in your home cloud and see the links at: http://localhost:4444/mutant/asset/Link
This is written as of version 0.x so the links may change - the use case however will be maintained up-to-date in the wiki, at http://wiki.homecloud.ca/savedlink
Friday, October 2, 2009
Modern Applications
ABSTRACT: today it is unacceptable to have any application built as an independent islands of functionality. It is necessary to expose functionality via simple protocols (http).
Really, it is unacceptable today to have any application built as an independent piece of functionality. No application is or should be complex enough to do EVERYTHING. Thus, since we do not view our users as the mandatory human servers of the omnipotent computer -- with the noble lifetime goal of clicking through the menus, dialogs, wizards and buttons that the all-mighty programmer has imposed on them -- all application components NEED TO OFFER API-based access to a basic set of services/functions/objects/whathaveyou.
These span a large number of functional areas, from controlling the application remotely, scripting its behavior, input/output/logging etc, so we'll take them one-by-one in future posts.
Point being that applications become interoperable and subject to automation. There's no other way really to automatically turn down the volume of the DVD player because you answered a call on skype! OR have a tweet on your cellphone when the torrent has finished donwloading the latest CBC show.
--- Interoperability == standardisation?
This thinking is normal to any Unix hacker, since they allways did "find|grep|cut|wc|sort" but it seems too complicated for anybody else to comprehend, especially window-heads.
With physical devices, standardisation is, granted, not easy. Standards arise from a need which is already fulfilled by existing devices, cables and plugs. Then the plugs get standardised and devices become interoperable.
The same was true in the software world (find|grep), but it's been false for a long time, especially since the advent of the stupidifying mouse and the un-parseable pixel.
Command lines have always been around and http has also been around for a long time. There really is no reason not to combine both, when all you want is users to use the functionality your code has to offer.
Ideally, all applications would be certified as "open" and "interoperable" and we will get there, in time. DLNA/UPNP is an example of such an interoperable framework, including certification. So is OSS/J (a set of telecom APIs) and others.
--- using http at rest to describe and interact with the object-oriented world
So, what should ideally happen? We'd have unified protocols for access and interoperability. HTTP, telnet, command lines come to mind. Formats are also an obvious need: HTML/XML/JSON/text. Let REST dictate how things work, but only a modicum of human intervention can be mandated.
Beyond the needs, there's the wants. We'd like that each would expose their internal models (objects, services, methods, actions, functionality) in a standard way, parseable and understandable by others.
If you extend that to the interoperable web, you get the semantic web. Well, almost, since that's been designed by DBAs - they'd like to call it the "data web" and hide logic in a view that offers more data :). Sorry, couldn't help it!
I live in a world surrounded by objects I'm interacting with. Data/information has a very important role to play, but it's not the end-all. My newspaper can not only filter for me the latest developments on that accident, but can also manage my account and micro-payments. Having knowledge of an intermediary PayPal only serves to confuse me and keep my mind busy with concepts I don't care about, since i already told my "gate keeper" that I trust my newspaper somewhat...
The semantic web guys have it right, though. Exposing standardized schemas of the applications's objects and functionalities is the way to go. Scoping these (my "train" is different than your "train") makes obvious sense (think namespaces).
---- So, vat do you vant?
In the B2B universe (now turned SOA) there's lots of WS-based standards, including security, identity exchange etc. These don't bode well on the web, though. Why write things twice? It has to be simple-over-http. PERIOD, dumby.
So, each modern application has:
- embedded http server
- exposing functionality/internal models etc
- designed to be interoperable
I would like everyone to stop buying and using any application that doesn't meet these criteria. Harsh, but then i'm in a bad mood today...
------ So, what's a developer to do?
Embed an http server. In case you need a small, lightweight embedded web server, checkout my public project at http://razpub.googlecode.com . There's lots of others out there - actually I recommend you get one that supports the servlet standard and you do servlets.
Think about and define your business model, spell out your domain entities. Use less services and more objects when defining your API and bode nicely with REST.
Define your model in whatever format you want - just make sure it's an xml file :). We'll deal with these in a future post, but for now it must be objcet-oriented: each 'class' has 'attributes' and 'methods'. The methods have a name and a list of arguments. Keep all types to String for now...assume all interaction is via URLs, which can't marshal bytecode - that's something we'll have to deal with.
Offer access to the entire business model via http, including content (values) and control (invoked methods).
Document all this very nicely in an embedded set of html pages. No smarts neccessary. Simple solutions always work better than complex ones.
If you're looking for an asset/modelling/http object interface framework, checkout the com.razie.pub.assets package of my razpub project.
Stick to the REST principles for now, until my "REST is bad" post is posted.
Modularity - allow extensions of functionality. Since the future is OSGi, may I suggest an OSGi compliant server - mine will be but it's not.
And generally, don't forget to have fun!
P.S. Just to give a concrete example, the VLC player is a great one. It has several interfaces, including telnet and http and you start whichever you want...
Really, it is unacceptable today to have any application built as an independent piece of functionality. No application is or should be complex enough to do EVERYTHING. Thus, since we do not view our users as the mandatory human servers of the omnipotent computer -- with the noble lifetime goal of clicking through the menus, dialogs, wizards and buttons that the all-mighty programmer has imposed on them -- all application components NEED TO OFFER API-based access to a basic set of services/functions/objects/whathaveyou.
These span a large number of functional areas, from controlling the application remotely, scripting its behavior, input/output/logging etc, so we'll take them one-by-one in future posts.
Point being that applications become interoperable and subject to automation. There's no other way really to automatically turn down the volume of the DVD player because you answered a call on skype! OR have a tweet on your cellphone when the torrent has finished donwloading the latest CBC show.
--- Interoperability == standardisation?
This thinking is normal to any Unix hacker, since they allways did "find|grep|cut|wc|sort" but it seems too complicated for anybody else to comprehend, especially window-heads.
With physical devices, standardisation is, granted, not easy. Standards arise from a need which is already fulfilled by existing devices, cables and plugs. Then the plugs get standardised and devices become interoperable.
The same was true in the software world (find|grep), but it's been false for a long time, especially since the advent of the stupidifying mouse and the un-parseable pixel.
Command lines have always been around and http has also been around for a long time. There really is no reason not to combine both, when all you want is users to use the functionality your code has to offer.
Ideally, all applications would be certified as "open" and "interoperable" and we will get there, in time. DLNA/UPNP is an example of such an interoperable framework, including certification. So is OSS/J (a set of telecom APIs) and others.
--- using http at rest to describe and interact with the object-oriented world
So, what should ideally happen? We'd have unified protocols for access and interoperability. HTTP, telnet, command lines come to mind. Formats are also an obvious need: HTML/XML/JSON/text. Let REST dictate how things work, but only a modicum of human intervention can be mandated.
Beyond the needs, there's the wants. We'd like that each would expose their internal models (objects, services, methods, actions, functionality) in a standard way, parseable and understandable by others.
If you extend that to the interoperable web, you get the semantic web. Well, almost, since that's been designed by DBAs - they'd like to call it the "data web" and hide logic in a view that offers more data :). Sorry, couldn't help it!
I live in a world surrounded by objects I'm interacting with. Data/information has a very important role to play, but it's not the end-all. My newspaper can not only filter for me the latest developments on that accident, but can also manage my account and micro-payments. Having knowledge of an intermediary PayPal only serves to confuse me and keep my mind busy with concepts I don't care about, since i already told my "gate keeper" that I trust my newspaper somewhat...
The semantic web guys have it right, though. Exposing standardized schemas of the applications's objects and functionalities is the way to go. Scoping these (my "train" is different than your "train") makes obvious sense (think namespaces).
---- So, vat do you vant?
In the B2B universe (now turned SOA) there's lots of WS-based standards, including security, identity exchange etc. These don't bode well on the web, though. Why write things twice? It has to be simple-over-http. PERIOD, dumby.
So, each modern application has:
- embedded http server
- exposing functionality/internal models etc
- designed to be interoperable
I would like everyone to stop buying and using any application that doesn't meet these criteria. Harsh, but then i'm in a bad mood today...
------ So, what's a developer to do?
Embed an http server. In case you need a small, lightweight embedded web server, checkout my public project at http://razpub.googlecode.com . There's lots of others out there - actually I recommend you get one that supports the servlet standard and you do servlets.
Think about and define your business model, spell out your domain entities. Use less services and more objects when defining your API and bode nicely with REST.
Define your model in whatever format you want - just make sure it's an xml file :). We'll deal with these in a future post, but for now it must be objcet-oriented: each 'class' has 'attributes' and 'methods'. The methods have a name and a list of arguments. Keep all types to String for now...assume all interaction is via URLs, which can't marshal bytecode - that's something we'll have to deal with.
Offer access to the entire business model via http, including content (values) and control (invoked methods).
Document all this very nicely in an embedded set of html pages. No smarts neccessary. Simple solutions always work better than complex ones.
If you're looking for an asset/modelling/http object interface framework, checkout the com.razie.pub.assets package of my razpub project.
Stick to the REST principles for now, until my "REST is bad" post is posted.
Modularity - allow extensions of functionality. Since the future is OSGi, may I suggest an OSGi compliant server - mine will be but it's not.
And generally, don't forget to have fun!
P.S. Just to give a concrete example, the VLC player is a great one. It has several interfaces, including telnet and http and you start whichever you want...
Subscribe to:
Posts (Atom)